

تست UI
می 10, 2021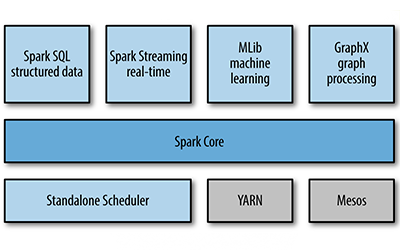

تفاوتهای کاربردی RDD, DataFrame و DataSet
از زمان به وجود آمدن Apache Spark در یازده سال پیش، این پلتفرم به طرز چشمگیری و به طور مداوم اولین انتخاب توسعه دهندگان داده های بزرگ بوده است. توسعه دهندگان همیشه آن را به دلیل ارائه API های ساده و قدرتمند که می توانند تقریبا هر تجزیه و تحلیل را روی داده های بزرگ انجام دهند، پسندیده اند. در این مقاله، می کوشیم که به یکی از جنبه های جذاب تحلیل داده توسط اسپارک یعنی RDD ها بپردازیم.
Spark یک موتور پردازش توزیع شده است، یعنی این امکان را به ما می دهد که در یک محیط توزیع شده (در یک Cluster شامل چندین server) بتوانیم عملیات ETL و آماده سازی داده ، تحلیل داده ،پیاده سازی الگوریتم های یادگیری ماشین ، پردازش جریان و غیره را انجام دهیم.
در شکل زیر مولفه های Spark را می توانیم ببینیم که روی Spark Core پایه گذاری شده اند:

مولفه های Spark
Spark برای مدیریت منابع توزیع شده در خوشه از Standalone Scheduler به شکل پیش فرض استفاده می کند، اما می توان از Hadoop Yarn ، Mesos ، EC2 و غیره نیز استفاده کرد.
نکته ی اساسی در مورد Spark این است که بر خلاف MapReduce، data sharing بهینه تری دارد و به شکل In-memory کار می کند و این یکی از دلایل اساسی بالا بودن سرعت Spark نسبت به MapReduce است.

اجرا یک Job در Spark به شکل In-memory

اجرا یک Job در Map reduce به شکل Disk Base
یکی از مهمترین صورت مسئله ها در یک پروژه ی داده، نحوه ی ذخیره سازی داده برای نگهداری و همچنین مدل داده ای برای پردازش و تحلیل است. در بخش تحلیل، اسپارک از یک مدل داده ای In-memory به نام RDD (resilient distributed dataset) استفاده می کند که قابلیت تقسیم شدن به چند پارتیشن را نیز دارد .

RDD می تواند به چندین Partition تقسیم شود.
- تمام عملیات ها درSpark مانند Transformation و Action روی RDD ها انجام می شود.
ویژگی های RDD
- انعطاف پذیری و تحمل خطا (Resilience): RDD ها به طور خودکار اطلاعات اصلی داده ها را برای بازیابی آن در صورت خرابی دنبال می کنند که به آن تحمل خطا (fault tolerance) می گویند.

نحوه ی توزیع شدن پارتیشن های یک RDD در Worker Node ها
- Lazy evaluation: این اصطلاح به این معناست که هنگام فراخوانی Transformation ها در RDD، آن ها بلافاصله اجرا نمی شوند بلکه Spark عملیات های اعمال شده را از طریق یک گراف بدون دور (DAG) حفظ می کند. در واقع Spark RDD همان داده ای است که از طریق Transformation ها مرحله به مرحله ایجاد کرده ایم و زمانی که یک Action مثل collect و count و ... اجرا شود، Job ما نیز اجرا می شود.
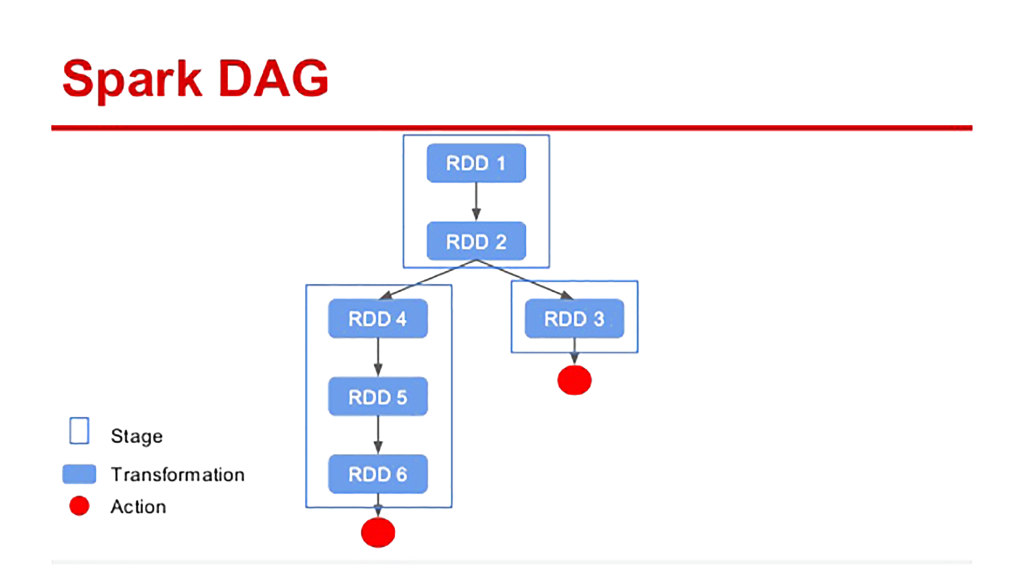
در هر Job یک Spark DAG ایجاد می شود که در نهایت به یک خروجی توسط Action برسیم
- تغییر ناپذیری (Immutability): از ویژگی های مهم RDDها می توان به تغییر ناپذیر (immutable) بودن آن ها اشاره کرد، به این معنا که وقتی داده ها را در یک RDD قرار می دهیم و می خواهیم تغییری ایجاد کنیم باید یک RDD دیگر با تغییرات اعمال شده بسازیم. در واقع RDDها معادل تعریف متغیر در python هستند و برای انجام هر Transformation یک RDD ساخته می شود.

انجام Transformation که منجر به ساخت RDD ها می شود و انجام Action که Job را اجرا می کند
- محاسبات درون حافظه (In-memory computation): هر داده ای که تولید می شود روی RAM ذخیره می شود و پردازش بر اساس داده های روی RAM انجام می شود بنابراین دسترسی و پردازش به مراتب سریع تر است.
- Partitioning : میتوان RDD ها را به قسمت های کوچکتری تقسیم کرد، که برای اجرا عملیات به Executer های متفاوت ارسال شوند.
Dataset و DataFrame
با وجود تمام قابلیت های RDD، با رشد استفاده از این پلتفرم دو نوع مدل داده ای دیگر نیز در نسخه های بعدی به آن اضافه شد.

مدل داده ای Spark بر اساس تاریخ ارائه
در واقع در سطح پایین، Spark فقط RDDها را می شناسد، یعنی ساختار داده ای که با آن کار می کند RDD است، بنابراین می توان گفت که Dataset و DataFrame نوعی API سطح بالا برای کار با داده های ساخت یافته هستند که Spark در لایه ی پایین با منطق RDD با آن ها برخورد می کند.
همچنین در RDD باید به شکل دستی Schema را تعریف کنیم اما در Dataframe و Dataset این اتفاق به شکل خودکار رخ می دهد.
DataFrame ها را می توان یک مجموعه ی توزیع شده از داده های ساخت یافته در ستون هایی نام گذاری شده دانست، که معادل جداول RDBMS ها هستند. با این جداول می توان به کمک Spark SQL تعامل داشت و همچنین می توان DataFile های ساخت یافته، جداول Hive،جداول پایگاه داده ی خارجی یا RDD ها را به آن ها تبدیل نمود. DataFrame ها در زبان هایی مثل پایتون و R که نیازی به تعریف نوع داده نیست استفاده می شوند.
Dataset ها یک مفهوم شبیه به DataFrame ها هستند اما در زبان های برنامه نویسی مثل Java و Scala که نیاز به تعریف نوع داده هست (statically typed) استفاده می شوند و به عنوان یک API جدید در Apache Spark 1.6 معرفی شدند. در عملیات تجمیع از RDD ها سریع ترند اما نسبت به Dataframe ها کند می باشند. این امکان وجود دارد که Dataset از Object های JVM ایجاد شود و بعد با استفاده از Transformationهایی از قبیل filter ، Map و Flatmap و غیره کنترل شود.

DataFrame vs Dataset